
Scalable Offline Identity Graph for Marketing Intelligence
Delivered a large-scale offline identity management system that enables organizations to unify fragmented consumer data and derive actionable insights for targeted marketing campaigns.
The platform processes high-volume datasets such as purchase history, website activity, and consumer interests, and links them to a unique consumer identity using advanced matching techniques.
This unified identity layer powers segmentation, targeting, and campaign analytics at scale.

Implementation Process
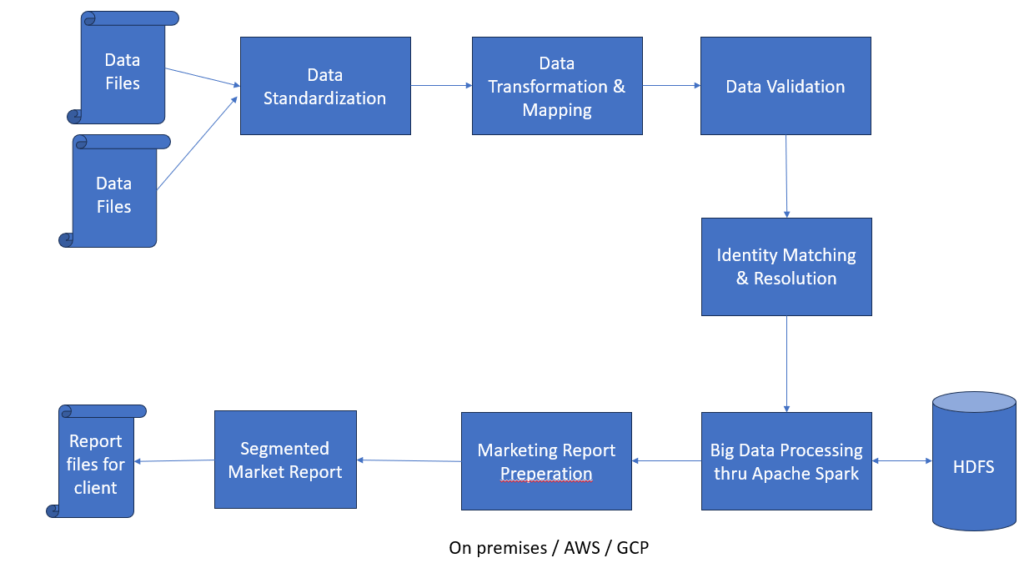
Data Processing Layer
Batch data received from multiple clients:
- Purchase transactions
- Behavioral and interest data
Supported ingestion of large-scale structured and semi-structured datasets
Data Cleansing & Standardization
Data processed through cleansing pipelines:
- Attribute standardization
- Deduplication
- Format normalization
Identity Matching & Resolution Engine
Core system to link consumer data across sources Built logic to:
- Create a unique consumer identity (Identity Graph)
- Identify unique consumer attributes
- Connect fragmented records
Big Data Processing Layer
Built on Hadoop Distributed File System (HDFS) Used Apache Spark for:
- Data aggregation and segmentation
- Distributed data processing
- Large-scale high speed data processing.
Data Storage & Access
Processed data stored in:
- HDFS (data storage)
- Optimized for bulk storage and large-scale querying
Structured datasets prepared for:
- Consumer segmentation
- Campaign targeting
Analytics & Reporting Layer
Generated insights for:
- Consumer segmentation for marketing
- Interest-based targeting
- Campaign audience selection
Delivered outputs for:
- Data-driven decision making
- Marketing campaign execution
Technology Stack
- Java, Scala
- Python
- Spark & Hadoop
- AI & ML